Direct Numerical Layout Generation for 3D Indoor Scene Synthesis via Spatial Reasoning
Generated Samples
Coarse-Grained Prompt:
A computer classroom with individual computer desks, ergonomic chairs, a projector screen, a table, a printer, and a network hub
A hallway with a shoe rack, coat hooks, mirror, bench, umbrella stand, table, and a rug
A kitchen with a refrigerator, stove, sink, countertop, dining table, and several cabinets, along with a few bar stools
Medium-Grained Prompt:
In a home theater, a large screen is positioned against a wall, flanked by two speakers. In front of it, a round coffee table holds popcorn and potato chips. A sofa sits behind the coffee table, and several bean bags are arranged around it
A garage features a large car centrally located, with storage shelves lining the back wall. A workbench and a toolbox are positioned beneath a pegboard, while a bicycle and a lawnmower are arranged nearby
A classroom is furnished with a teacher's desk at the front, facing an arrangement of student desks and chairs. A whiteboard is mounted on the front wall, and a projector hangs from the ceiling. A tall bookshelf also stands in the side
Fine-Grained Prompt:
A foosball table is at the center of a game room, with two gaming chairs positioned on its long sides. A large TV sits on a wooden stand against the wall, behind the foosball table. To the left of the TV is a silver mini fridge. On the other wall, a tall bookshelf is filled with board games. Two posters are displayed on the walls, one next to the bookshelf and one next to the TV
A wine cellar with storage and tasting areas is depicted. Along two opposing walls, extensive wooden racks are filled with wine bottles. On another wall, a collection of oak barrels is stacked, with a wooden crate. A tasting table, accompanied by a single chair, is centrally located within the room. On the table, there are two wine glasses and a corkscrew. A temperature gauge is mounted on the wall above the oak barrels, and two circular lighting fixtures on the ceiling
A wooden table holds a laptop on the front left corner, with a glass of colored pencils placed to its right. At the center back of the table sits a blue vase filled with flowers, and in front of the vase lie a pair of black-framed glasses. On the left side of the table is a white coffee cup, while a wooden chair is positioned in front of the table
Comparison Results

Abstract
Realistic 3D indoor scene synthesis is crucial for Embodied AI and digital content creation. However, achieving high fidelity, strong generalization and precise controllability remains challenging due to complex semantic and physical constraints. Existing methods follow two paradigms: (1) Training models on layout datasets to directly generate numerical 3D layouts, which often generalize poorly to unseen room types; (2) Using LLMs/VLMs to produce open-vocabulary intermediate representations (e.g., scene graphs) followed by constraint-based optimization, improving plausibility but sacrificing flexibility due to predefined rules. Both approaches struggle to adapt to fine-grained user requirements. We introduce DirectLayout, a framework that directly generates numerical 3D layouts from text descriptions, without relying on intermediate representations and constrained optimization. DirectLayout decomposes the generation into three stages: producing a Bird's-Eye View (BEV) layout, lifting it into 3D space, and refining object placements for plausibility. To enable explicit spatial reasoning and help the model grasp basic principles of object placement, we employ Chain-of-Thought (CoT) activation based on the 3D-Front dataset. Additionally, we design CoT-Grounded Generative Layout Reward to enhance generalization and spatial planning. During inference, DirectLayout addresses asset-layout mismatches via Iterative Asset-Layout Alignment through in-context learning. Extensive experiments demonstrate that DirectLayout achieves impressive semantic consistency, generalization and physical plausibility.
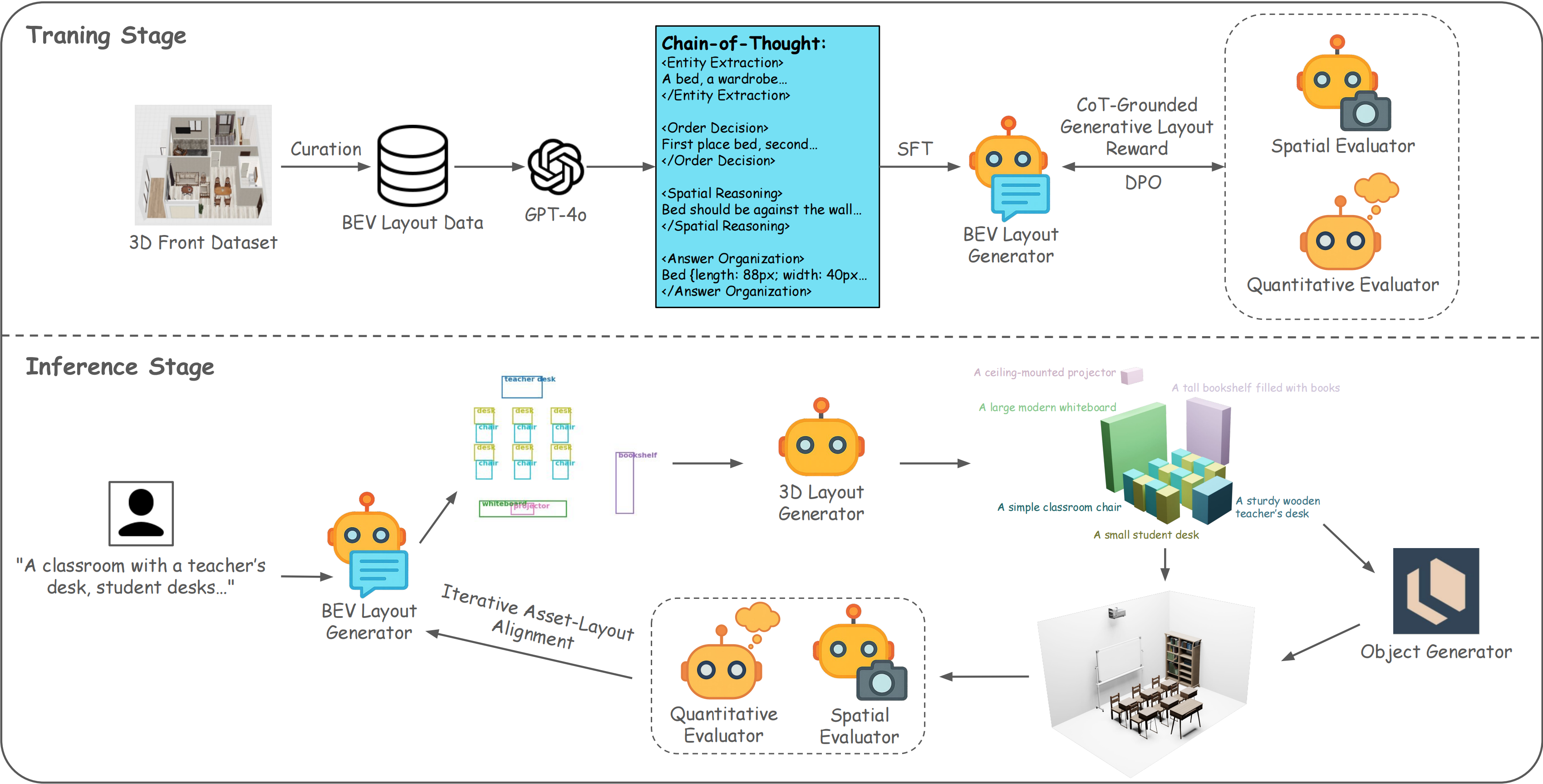
Method
Training Stage: BEV Layout Generator is first fine-tuned on BEV layouts curated from the 3D-Front dataset, guided by CoT annotations generated by GPT-4o. Subsequently, it is further optimized through DPO, leveraging CoT-Grounded Generative Layout Reward derived from Spatial Evaluator (VLM) and Quantitative Evaluator (reasoning LLM).
Inference Stage: Given a text prompt, BEV Layout Generator produces a 2D layout, which is then lifted to a 3D layout by 3D Layout Generator. Iterative Asset-Layout Alignment refines the 3D scene by using the Spatial and Quantitative Evaluators to provide feedback to the layout generators, ensuring consistency between the layout and generated 3D assets from an object generator.